In semiconductor manufacturing, knowing that your process is in control is only half the picture. The real question is: can your process consistently produce material that meets the specification? A control chart tells you if the process is stable. A capability analysis tells you if that stable process is good enough.
This post builds directly on our earlier tutorial on SPC Charts in R for Semiconductor Process Monitoring. If you have not read that post yet, it covers X-bar and R charts using the qcc package, and we will be using the same simulated LPCVD silicon nitride dataset here. You can also refer back to that post for an introduction to R if needed.
What Process Capability Actually Measures
Process capability compares the natural variation of your process against the specification limits defined by the product design. The key insight is that control limits and specification limits are two different things:
- Control limits are statistically derived from your process data (±3 sigma from the process mean). They tell you whether the process is stable and predictable.
- Specification limits are engineering requirements set by product design. They define what is acceptable for the customer.
A process can be in statistical control (all points within control limits) but still incapable of meeting the specification if the natural variation is wider than the spec tolerance. This is exactly why capability analysis matters.
The Capability Indices: Cp and Cpk
Two indices form the backbone of capability analysis in manufacturing:
Cp (Process Capability Index) measures the potential capability of the process assuming it is perfectly centered between the specification limits:
Cp = (USL - LSL) / (6 * sigma)Cp tells you how many times the natural process variation (6 sigma) fits inside the spec tolerance. A Cp of 1.0 means the process variation exactly matches the spec width. A Cp of 1.33 means the spec width is 33% wider than the process variation, which is generally considered the minimum acceptable for a stable process. A Cp of 1.67 or higher is typical for critical parameters.
Cpk (Process Capability Index, adjusted for centering) accounts for how centered the process is within the spec limits:
Cpk = min( (USL - mean) / (3 * sigma), (mean - LSL) / (3 * sigma) )Cpk penalizes you for being off-center. A process can have a high Cp but a low Cpk if its mean has drifted closer to one spec limit. This is common in semiconductor manufacturing where processes often run slightly above target to ensure device performance, sacrificing some margin on the upper end.
In practice, Cpk is the more useful metric because it reflects reality. A process can be capable on paper (high Cp) but still produce out-of-spec material if the mean is not centered (low Cpk).
Capability Analysis in R with the qcc Package
Using the same synthetic thickness data from the SPC post, we can run capability analysis with a single function call. The qcc package provides process.capability(), which takes a qcc object of type “xbar” and specification limits as inputs.
Let us assume the engineering specification for our LPCVD silicon nitride film is 2000 ± 60 angstroms, which gives an LSL of 1940 and a USL of 2060:
library(qcc)
# Using the same xbar chart object from the SPC post
set.seed(42)
n_batches <- 25
n_wafers <- 5
thickness <- matrix(nrow = n_batches, ncol = n_wafers)
for (i in 1:n_batches) {
drift <- ifelse(i > 20, (i - 20) * 5, 0)
thickness[i, ] <- round(rnorm(n_wafers, mean = 2000 + drift, sd = 15), 1)
}
batch_thickness <- as.data.frame(thickness)
xbar_chart <- qcc(batch_thickness, type = "xbar")
# Process capability analysis
spec_limits <- c(1940, 2060) # LSL, USL
cap <- process.capability(xbar_chart, spec.limits = spec_limits)
print(cap)Running the above code yields the following graph
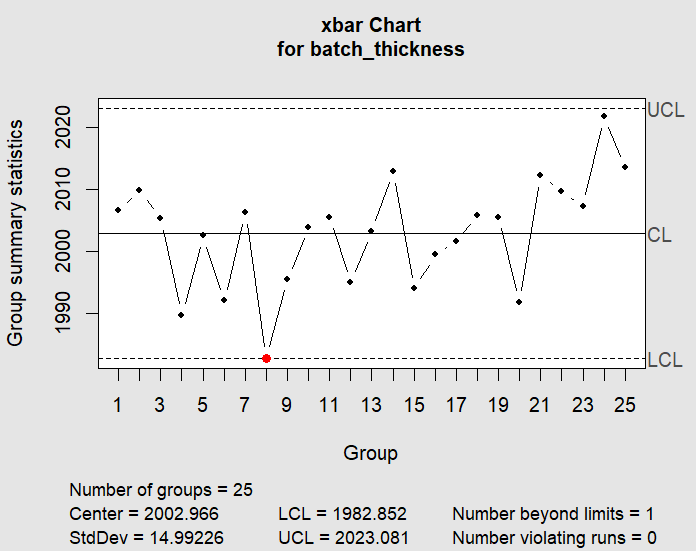
The process.capability() function generates a histogram overlay showing the process distribution against the specification limits, with the capability indices printed. For our simulated data, the output will look something like:
Process Capability Analysis
$nobs
[1] 125
$center
[1] 2002.966
$std.dev
[1] 14.99226
$target
[1] 2000
$spec.limits
LSL USL
1940 2060
$indices
Value 2.5% 97.5%
Cp 1.334022 1.168084 1.499706
Cp_l 1.399976 1.245746 1.554205
Cp_u 1.268068 1.126833 1.409302
Cp_k 1.268068 1.099776 1.436359
Cpm 1.308651 1.143501 1.473546
$exp
Exp < LSL Exp > USL
0 0
$obs
Obs < LSL Obs > USL
0.000 0.008We also get a histogram:
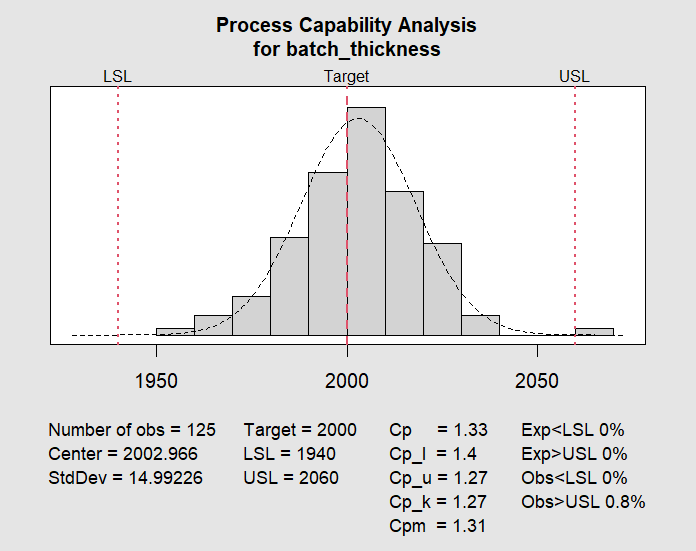
A Cpk of 1.27 is below the commonly accepted threshold of 1.33, which makes sense because the drift in the final batches pulled the overall mean slightly upward and increased the overall variation estimate. This tells us that even though most individual measurements fall within spec, the process does not have enough margin to absorb the drift we observed.
Interpreting the Results
The capability output includes both short-term and long-term estimates. The qcc package reports based on the within-subgroup variation derived from the R chart, which represents the inherent short-term process capability. Key things to look for:
- Cpk < 1.0: The process is not capable. Out-of-spec material will be produced regularly. Immediate action is needed to either reduce variation or shift the mean.
- Cpk between 1.0 and 1.33: Marginal capability. The process can meet spec under ideal conditions, but any shift or increase in variation will produce defects. This is where most semiconductor processes operate for non-critical layers.
- Cpk between 1.33 and 1.67: Capable process. The process has enough margin to absorb small shifts without producing defects. This is the target range for most critical parameters.
- Cpk > 1.67: Highly capable. The process has significant margin. For ultra-critical parameters in advanced nodes, this level is often required.
In our example, a Cpk of 1.25 is marginal. The root cause is visible in the original X-bar chart: the upward drift in batches 21 through 25 shifted the overall mean and inflated the standard deviation estimate. Without that drift, the process would easily exceed a Cpk of 1.33. This illustrates why capability analysis and control charts should always be used together. The control chart identifies when and how the process shifted; the capability analysis quantifies the impact on yield.
Pp and Ppk: Long-Term Capability
The qcc package also reports Pp and Ppk, which use the overall standard deviation instead of the within-subgroup estimate. The distinction matters:
- Cp and Cpk use within-subgroup variation (short-term). They represent what the process can achieve when it is stable and in control.
- Pp and Ppk use the total standard deviation of all data points (long-term). They represent what the process actually delivered, including any shifts, drifts, and batch-to-batch variation.
A large gap between Cpk and Ppk indicates that the process has significant between-subgroup variation or instability. In our example, the drift causes Ppk to be noticeably lower than Cpk, confirming that the process needs corrective action before capability can improve.
Practical Considerations for Process Engineers
A few things to keep in mind when applying capability analysis in a real fab environment:
- Capability requires stability. Calculating Cpk on an out-of-control process is meaningless. Always check your control charts first.
- Sample size matters. The qcc default of at least 20 subgroups is the minimum for a reasonable estimate. Fewer subgroups produce unreliable sigma estimates.
- Specifications are not negotiable. If Cpk is low, the solution is to reduce variation or shift the mean, not to widen the specs. That said, understanding whether the spec is a true device requirement or a legacy limit can guide prioritization.
- Cpk should be tracked over time. A single capability study is a snapshot. Tracking Cpk on a regular basis (weekly or monthly) reveals whether process improvements are actually working.
- Non-normal data requires care. The qcc package assumes normality for capability calculations. If your parameter is not normally distributed (particle counts, defect densities), consider transformations or distribution-specific methods.
What Comes Next
With control charts and capability analysis in place, you have the two foundational tools for process monitoring. The next step is often extending this framework to handle multiple correlated parameters simultaneously, which is where multivariate SPC (Hotelling’s T²) comes in. We will cover that in a future post.
For readers interested in quantifying process improvements more rigorously, our upcoming post on Propensity Score Matching for Pre/Post CIP Analysis will show how to apply causal inference methods to evaluate the real impact of chamber maintenance events.
Conclusion
Process capability analysis transforms control chart data into a clear, quantitative answer to the question every process engineer faces: can this process meet the specification? Using the qcc package in R, you can go from raw thickness measurements to a Cpk value and a capability histogram in just a few lines of code. The combination of control charts for stability and capability analysis for performance gives you a complete monitoring framework that works across deposition, etch, lithography, and any semiconductor process.